

Posted on 16 September 2021.
Why do you need a monitoring solution?
Everything is going according to plan, your app is in production and cruising. Later this week, a new update is deployed in production. You start to experience slow-downs on your platform. Customers are reporting issues, and you are desperately trying to find out what is happening.
A couple of days later, you release a new version that improves the performance. And now everything is crashing. You have no idea what is not working. Your queries are slow, your application is not responding. All the projects' owners form a war room and ask the devs for an answer. Everyone is frantically searching for an answer.
A couple of hours later, the issue is found. When the last release that fixed the issue went to production, it was also bundled with a security update that introduced a bug in the application. Now that you know what happened, you fix the issue and everyone can finally go to bed.
What follows is a couple of weeks of frustration, everyone is looking for someone to blame and a solution. You spend the next week creating standards for new releases, new test suites, and many more kinds of useful features.
What if I told you that this could have been prevented a long time ago? What if you had something that could have helped you prevent this, or at least told you what happened in a couple of seconds without having your customer declare the incident?
Let's look at the cloud provider monitoring stacks then, as it tends to be the first one you use.
Is the monitoring stack of cloud providers good?
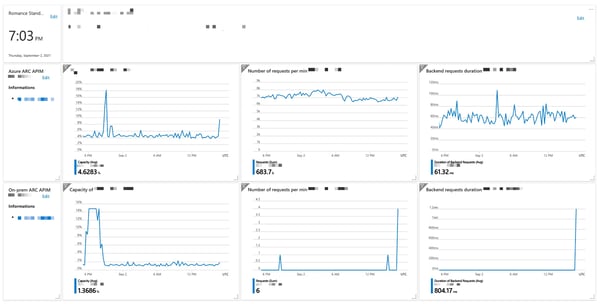
You probably are hosting your infrastructure in a cloud provider. Therefore, you probably had the chance to work with one of their solutions. I'll talk briefly about Cloudwatch (AWS) and Azure Monitor as there are the ones that I know best.
Is the monitoring stack of cloud providers good?
So far, not so good!
Cloud providers tend to offer great resources to use (EC2, Managed Database, etc ...) but they are not known for their great dashboard.
Monitoring tends to follow the same rule. It is not intuitive. I've had the chance to try Azure Monitor (Azure) and Cloudwatch (AWS) and they are not easy to use. Creating dashboards for monitoring your resources is a tedious task and ends up with mismanaged and unusable dashboards, even with their great integrations with their resources.
Let me tell you a small story about Azure Monitor. In an ideal world, you want all of your cloud resources to be declared via some sort of Infrastructure as Code such as Terraform. Well, in Azure Monitor, dashboards that have been painfully created via Terraform don't even appear on the home page of Azure Monitor, you have to find the small link that says "link to dashboard" in order to access the dashboards created via Terraform.
I'm not saying Cloud Providers solutions are bad, however, the bigger your infrastructure the harder it is to use it to monitor it. They tend to be less customizable or hard to. For example, the customization of Cloudwatch alerts often tends to alert fatigue. You spent countless hours building a custom system that monitors your infrastructure in every way, but the thresholds are not ideal to use, and you don't have any fancy features such as prediction, Machine Learning error, etc ...
In my opinion, Cloud providers monitoring stack should only be used in the early stage of development. It is not easily sustainable in the long run. I hope that they'll drastically improve their solutions in order to reduce the number of tools required to create a secure and reliable infrastructure.
But then, what could we use? Let's take a look at the best open source monitoring solution out there.
Should you use Prometheus as a monitoring solution?
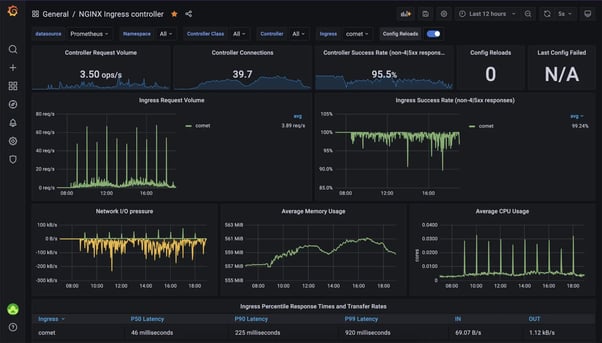
Prometheus is an open-source monitoring solution widely used in the DevOps world. It is a solution that can monitor many kinds of resources such as Kubernetes, Cloud provider resources, Ingress Controller, the weather, ...
You probably already know the good and bad sides of open source solutions, it is highly customizable. Open source projects tend to be open in order to let you adapt the solution to your liking.
Whenever you set up a Prometheus solution to monitor your applications/infrastructure you are met with hundreds of parameters to activate or not, to customize or not, leaving you in a big mess.
I've had the chance to implement and configure Prometheus on a couple of projects. Let me tell you, it is an extremely powerful tool that allows you to monitor almost anything. However, monitoring your infrastructure efficiently with it, requires you to become an expert.
So, is it worth it to you or do you have the time to become an expert in something when you clearly need to go to production as fast as possible? Do you have the resources internally to allow one of your colleagues to become an expert in Prometheus in order to build an efficient monitoring stack for your entire infrastructure? Is it worth the time for small organizations? Do you have the time to train somebody to become an expert in Prometheus? What happens when this person leaves?
These are hard questions to answer, it clearly depends on the goal of your organization.
I think you see my point. There are a lot of options to consider before using Prometheus. Going Open source is not always the best option for your company. Then, what is the best solution? Let's look at the last one then.
Is Datadog a good monitoring solution?
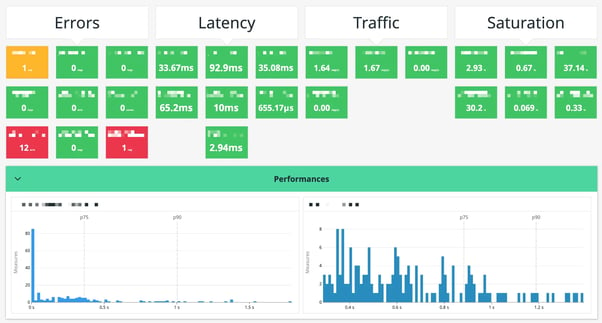
Damn it, I fell in love with this tool the second I laid my hands on it. It is really intuitive to use, easy to install but hard to master.
You can implement pretty much everything that you want, you can create awesome dashboards that monitor the golden metrics of your applications and infrastructure. You can easily create custom metrics based on your logs. Implement SLI/SLO efficiently and easily reduce alert fatigue with machine learning options that only send you alerts for behavior that is abnormal. You can analyze your logs for security alerts and so on.
The honeymoon lasted one month, but it ended abruptly when I received the first bill. Datadog is an awesome tool to use, however, it is really expensive. It can easily represent up to 20-30% of the price of your infrastructure.
The features of Datadog tend to make you stay on it, but before using it full scale on your projects, really think about the pricing. Understanding how billing works is an art in itself.
Datadog is great for two use cases:
- You have unlimited funds
- You have a small infrastructure with a high-reliability requirement.
If you don't fall in those categories, using Datadog will be an expensive and awesome experience.
One example is worth a thousand words. I've used Datadog on a project before, and we decided to monitor all the resources we had in production. We miss managed the installation and also monitored the UAT environment for 3 days. We quickly resolved the issue, however, at the end of the month we were billed for the production resources AND the UAT resources. Datadog bills you the monitoring of resources that have been present more than 1% of the time during the month. This is not sustainable if you have huge spikes during certain days or hours as you'll be charged for the maximum number of resources you have.
What should you use?
I've mainly said bad things about the different monitoring solutions that I presented in this solution, mainly in order to let you understand the drawbacks that each monitoring solution brings to the equation.
Here is a small list to help you choose the best monitoring solution.
- Small Project:
- Cloud Monitoring stack if no big requirements
- Datadog if you want your app to be highly reliable and secure
- Big Projects:
- Prometheus if you want to build a custom monitoring solution that really tends to your needs and if you have the resources to train someone.
- Datadog if you want simplicity and have deep pockets.
I hope that you understood all the implications of the different monitoring solutions. Did I cover all the bad aspects of each? 😉 Have you had personal experience with any of them that could help others? If so please feel free to share it in the commentaries. On the other hand, if you want to implement a custom monitoring solution on either the Cloud Providers, Prometheus, Datadog, etc ... feel free to reach us.