

Posted on 22 July 2019, updated on 18 December 2023.
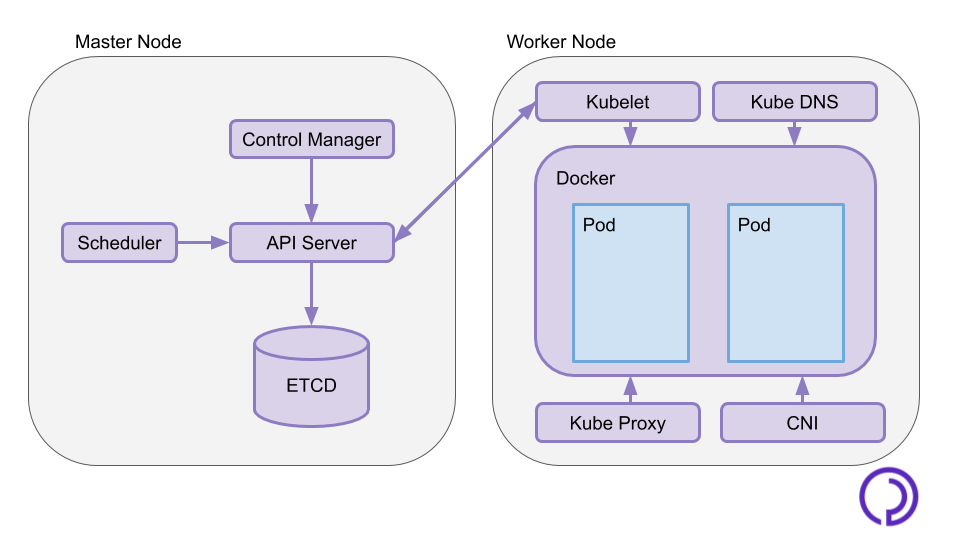
Architecture of a master node : the kube-system pods
A master node hosts the Kubernetes Control Plane, a set of services that administrate and orchestrate the whole cluster. These services run as pods in the "kube-system" namespace.
API Server
The API server is the central part of the Kubernetes Control Plane, it is a REST API which is the entrypoint to issue commands to the cluster. This is what you interact with when you write `kubectl` commands. It communicates with the different components of the master and the worker nodes to apply the user-desired state.
ETCD
ETCD is a high availability key value data store where the API stores the state of the cluster. This is also where credentials required to authenticate the requests you send to the API are stored. In order to have a resilient Kubernetes cluster, there should be at least 3 ETCD instances.
Scheduler
The scheduler monitors the available resources on the different worker nodes and schedules pods and other Kubernetes resources to nodes in consideration of this. The scheduler ensures the workload is evenly balanced across the cluster.
Controller Manager
The Controller Manager handles cluster orchestration. It oversees nodes leaving and joining the cluster and ensures the current state of the cluster is always in check with the desired state stored in ETCD. In case of a node failure, it will spin up new pods on the remaining nodes to match the wanted replica count.
Where your pods run : the worker nodes
The worker nodes form a cluster-level single deployment platform for Kubernetes resources. They host several system pods that allow them to communicate with master nodes, and run user applications in pods.
Container Runtime
The Container Runtime is the service that runs containers. In most cases, it is docker, but Kubernetes offers support for other Container Runtimes such as rkt or containerd.
Kubelet
Kubelet communicates with the API and applies the resources configuration on the node. It also reports to the master the health of the node. As it ensures pods run according to configuration, the Kubelet agent also runs on master nodes.
Container Network Interface
The CNI creates virtual networks across the whole cluster to allow containers and pods to communicate regardless of what node they run on. It yields pods virtual network interfaces and local IP addresses.
Kube DNS
The Kubernetes DNS Service allow pods to communicate with each other using their name or FQDN (Fully Qualified Domain Name) instead of their local IP.
Kube Proxy
The Kubernetes Service Proxy acts as a load balancer. It routes network traffic and forwards services to expose them outside of the cluster.
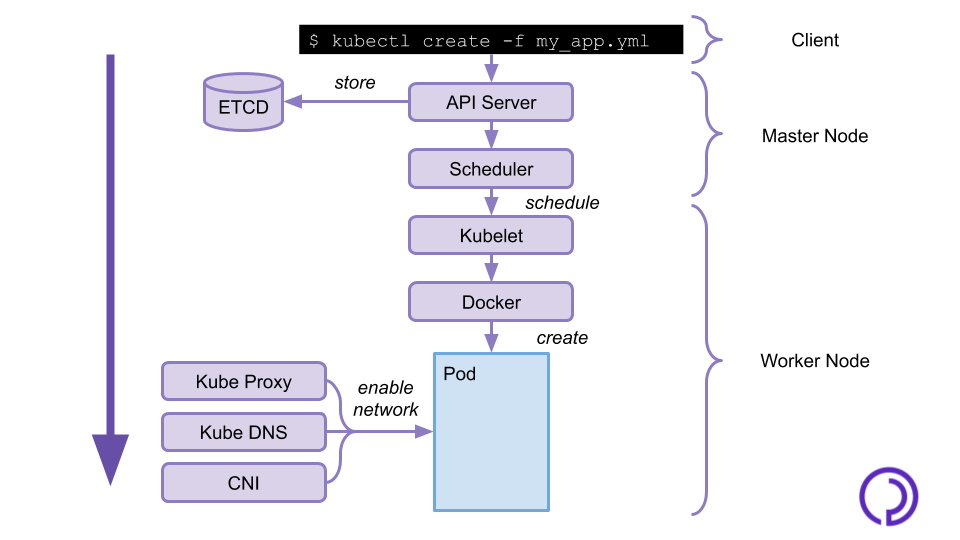
What happens when you deploy an app?
Now let's get into situation and review what exactly goes on when you deploy your containerized application on a Kubernetes cluster. You send the description of your application and its configuration to the API on the master node through the `kubectl` command line utility. The API will store this configuration in the ETCD, and the Sheduler will assign your application pods to worker nodes.
On the worker nodes, Kubelet will receive the description of its scheduled pods and will notify the container runtime to run them. Kube proxy, the container network interface and kube DNS will then ensure that the created pods have network access and can communicate with other pods on the node and in the cluster.
If a pod fails, it may be rescheduled on any worker node following the same procedure.
The cluster structure presented in this article is fairly standard, but is not the only one possible. There are clusters with a single node that acts as both a master and a worker, as well as some High Availability clusters where the Control Plane components are scattered across different nodes, and even replicated for resilience. In any case, all the components listed here are always present and interact with each other as explained above.
If you want to learn more about Kubernetes and how to use it in a production environment, you can check out our other blog articles and follow Padok on social media.