

Publié le 17 février 2021, mis à jour le 6 mars 2023.
Architecture générale de Kubernetes
Les créateurs de Kubernetes ont réussi à créer un système très complexe avec une architecture extrêmement simple faite de composants robustes.
Kubernetes est un système déclaratif (par opposition aux systèmes impératifs) : Les administrateurs décrivent un état souhaité, et Kubernetes se charge de faire en sorte que le cluster atteigne cet état souhaité.
Par exemple, il est possible de dire : “Nous avons besoin d’un Pod dans lequel il y aurait un seul conteneur. Ce conteneur exécutera une image nginx”. Si ce Pod n’existe pas encore, Kubernetes le créera. Si ce Pod existe déjà et correspond aux spécifications, Kubernetes ne fera rien.
Comment Kubernetes fonctionne ?
Un cluster Kubernetes peut se diviser en deux parties :
- Le Control Plane
- Les nodes (ou workers)
Le Control Plane est en quelque sorte le cerveau de Kubernetes. Les nodes sont les composants responsables d'exécuter les conteneurs. Chaque node possède un "Kubelet", chargé de communiquer avec le Control Plane.

Nous parlerons des nodes une autre fois ! Zoomons sur le Control plane :

On peut distinguer plusieurs composants :
Etcd
etcd un magasin de données clé-valeur distribué qui contient toutes les informations du cluster Kubernetes. En d’autre termes, toute ressource de Kubernetes est stockée dans etcd. Puisque c'est un magasin distribué, il est possible d'exécuter plusieurs etcd en même temps pour assurer la disponibilité et les performances du cluster. Etcd utilise l'algorithme de consensus RAFT pour déterminer la source de vérité.
API Server
C'est tout simplement une API REST chargée de lire et d'écrire dans etcd en CRUD (Create, Read, Update, Delete), et de notifier ses clients. Tous les composants du Control Plane communiquent au travers de l'API Server et l'API server est l'unique composant qui communique avec etcd. Cela simplifie grandement les choses !
A noter que etcd et l’API Server communiquent en REST également.
Lorsqu'on communique avec le cluster Kubernetes via kubectl par exemple, on effectue également des requêtes à l'API Server. Prenons l'exemple d'un client (cela peut être le schedule, un controller, ...) qui "s'abonne" aux événements relatifs au pods :
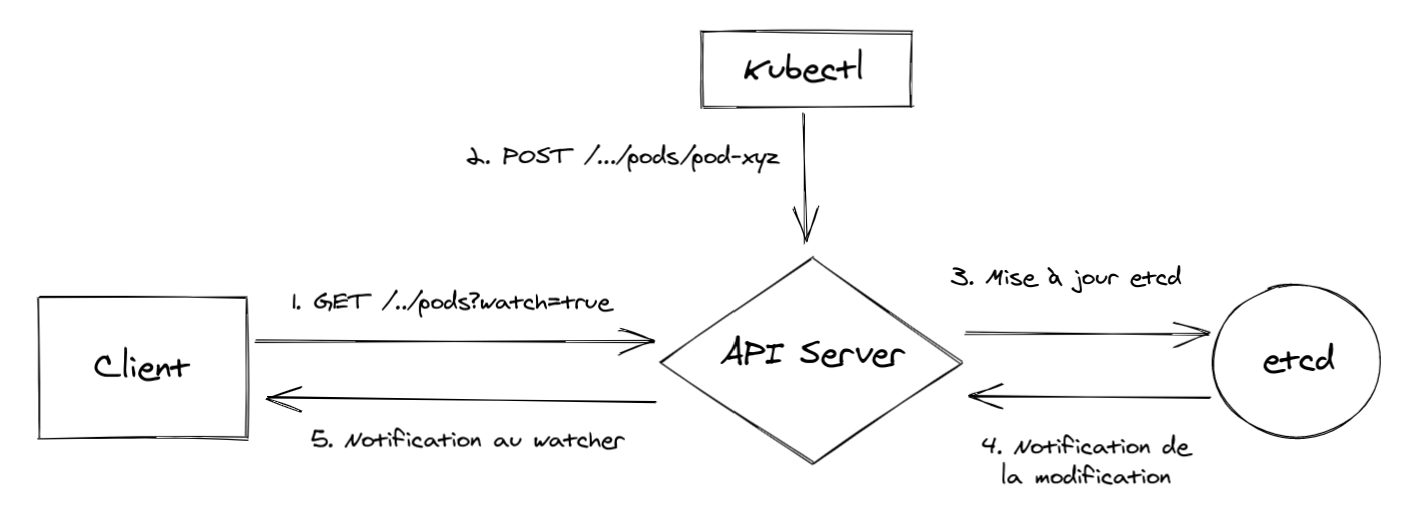
Lorsqu'un administrateur crée un pod via kubectl, l'API Server notifie alors les clients qui surveillent les ressources "pods".
Si l'on rentre un peu plus dans les détails, l'API Server traite les requêtes comme ceci :
- Authentication : L'API Server vérifie l'identité du client, grâce à des plugins d'authentification
- Authorization : L'API Server peut être configuré avec différent plugins d'autorisation qui permette de vérifier si le client peut effectuer l'action ou non
- Admission Control : Des plugins peuvent modifier la requête pour différentes raisons : Initialiser des champs manquant, vérifier si les politiques de sécurité sont respectées ...

Scheduler
Le scheduler est un client de l'API Server qui a pour rôle principal d'affecter un node aux pods. Dès qu'un pod est créé ou modifié, le scheduler va effectuer des actions en conséquence, c'est-à-dire effectuer des requêtes à l'API server pour modifier des ressources.
Les algorithmes de choix du node sont assez complexes, je ne rentrerai pas dans les détails.
Controller Manager
Le Controller Manager contient toutes sortes de controllers chargés de réconcilier l'état réel du cluster vers l'état souhaité. Chaque controller surveille des ressources, et effectue des requêtes à l'API Server si besoin pour corriger l'état du cluster.
Le Scheduler ne fait que assigner des nodes au pods, les contrôleurs s'assurent que l'état actuel du système converge vers l'état désiré.
Il existe de nombreux controllers, par exemple :
- Deployment controller
- StatefulSet controller
- Node controller
- Service controller
- Endpoints controller
- Namespace controller
- PersistentVolume controller
Il y a un controller pour presque toutes les ressources qui existent dans Kubernetes !
Les controllers ne communiquent pas entre eux, ils n'ont pas même pas conscience de l'existence d'autres controllers.
Kubelet
Le Kubelet est le seul composant du control plane qui est exécuté sur les worker nodes.
Chaque node possède un Kubelet, y compris le master node, chargé grosso modo de tout ce qui se passe sur le nœud. Il écoute l'API Server pour voir les pods qui lui ont été affectés et démarre alors les conteneurs du pod. Pour cela il communique avec le container runtime (Docker, CoreOS rkt, ...). Il surveille ensuite ses conteneurs et rapporte leurs statuts, leurs évènements et les ressources consommées à l'API Server.
Cloud Controller Manager
Le Cloud Controller Manager est un composant facultatif qui est chargé de communiquer avec le Cloud Provider, par exemple pour provisionner des serveurs qui serviront de nodes.
Exemple : La création d'un deployment
Voyons ensemble le déroulement d'un déploiement, de A à Z !

Avant toute chose, les controllers, le Scheduler et le Kubelet surveillent l'API Server pour leurs ressources respectives.
Accrochez-vous, on va créer un déploiement !

- On crée le déploiement, par exemple via kubectl
``` kubectl apply -f deployment.yaml
- Le Deployment Controller reçoit la notification de création de ressource ‘deployment’
- Pour que le deployment soit effectif, il faut des replicaset. Le Deployment Controller va donc faire appel à l'API Server et créer une ressource ‘replicaset’
- Le ReplicaSet Controller reçoit la notification de création de ressource ‘replicaset’
- Pour que le replicaset soit effectif, il faut des pods. Le ReplicaSet Controller va donc faire appel à l'API Server et créer le nombre de pods défini
- Le Scheduler reçoit la notification de création de ressources ‘pods’
- Le Scheduler va alors choisir un node (si possible) pour chaque pod, et faire appel à l'API Server pour modifier le pod
- Le Kubelet reçoit la notification qu'un nouveau pod est affecté à son node. Il va alors faire appel à Docker pour créer les containers définis
Et voila, la combinaison de briques logiques très simples a permis la création d'un déploiement ! Chaque composant est garant de sa ressource :
Si jamais un conteneur termine pour X raisons, le Kubelet va corriger la différence entre l'état souhaité et l'état réel, et recréer le pod.
Si jamais un pod est supprimé, le ReplicatSet Controller va créer un nouveau pod
Si jamais le replicaset est supprimer, c'est le Deployment Controller qui va recréer le replicaset
Nous avons dans cet article exploré plus en détail les différents composants du Control Plane de Kubernetes. On arrive à obtenir un système déclaratif très puissant avec des composants dont le rôle est simple et clairement défini. La création d’un déploiement n’a plus de secret pour vous !
J'espère que cet article vous aura permis de mieux comprendre le fonctionnement interne de Kubernetes, nous aborderons le sujet des nodes dans un futur article.;